Debugging CUDA JIT Codes with TotalView
The CUDA workflow followed by many programmers consists of writing a code by distributing it in various .cpp and .cu files, where the .cu files contain the __global__ functions, and the.cpp files contain allocations of memory for GPU spaces worked out by cudaMalloc, memory movements from host to device and vice versa performed by cudaMemcpy and __global__ function invocations.
Back to top
When to Use a JIT Compiler
In some cases, it is convenient or necessary to compile the __global__ functions at run-time, using Just-In-Time (JIT) compilation, instead of doing it in advance at compile-time. JIT compilation can be convenient to improve performance since run-time compilation occurs in a moment when all the hardware information is available.
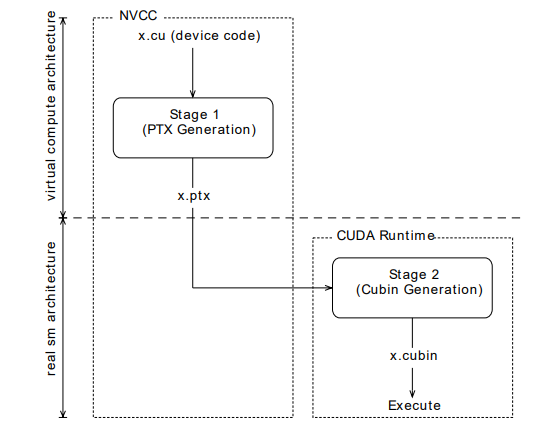
Just in time compilation of device code (source www.nvidia.com)
Back to topExample of Debugging a CUDA JIT Application
In this example we will use three files to demonstrate debugging a CUDA JIT application:
- tx_cuda_ptxjit.cpp
- tx_cuda_ptxjit.h
- tx_cuda_ptxjit_module.cu
The cpp file uses the Driver API to just-in-time compile (JIT) a Kernel from PTX code. Additionally, this sample demonstrates the seamless interoperability capability of CUDA Runtime and CUDA Driver API calls.
The cu file contains the CUDA kernel which prints “Hello World” from threadIdx.x and blockIdx.x
Environment
The example uses NVIDIA CUDA 11.7 and TotalView 2023.4
Other versions of CUDA that support JIT compilation should also work correctly.
You can request a TotalView evaluation here.
Compile the tx_cuda_ptxjit.cpp file
g++ -g tx_cuda_ptxjit.cpp -I/usr/local/cuda/include/ -L/usr/local/cuda/lib64 -o tx_cuda_ptxjit -lcuda -lcudartCompile the tx_cuda_ptjjit_module.cu file to ptx code
nvcc -g -G tx_cuda_ptxjit_module.cu -ptx -o tx_cuda_ptxjit_module.ptx(Note the -g and -G flags required.)
Start TotalView and debug the tx_cuda_ptxjit application
Command Line
totalview -args tx_cuda_ptxjit tx_cuda_ptxjit_module.ptxGUI
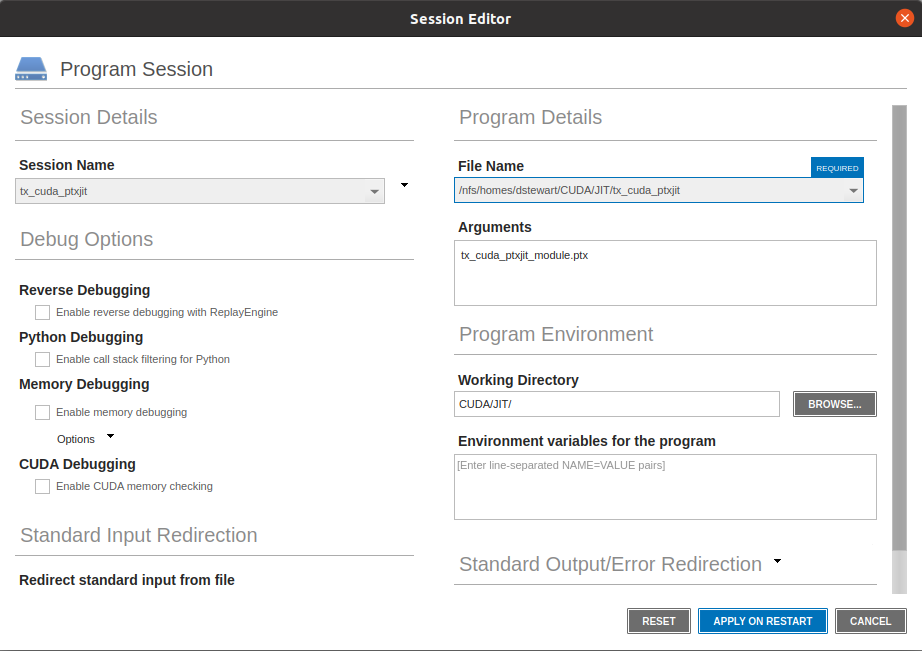
(Note the use of the Working Directory to specify the location of the PTX file.)
Back to topSet a pending breakpoint in the CUDA kernel
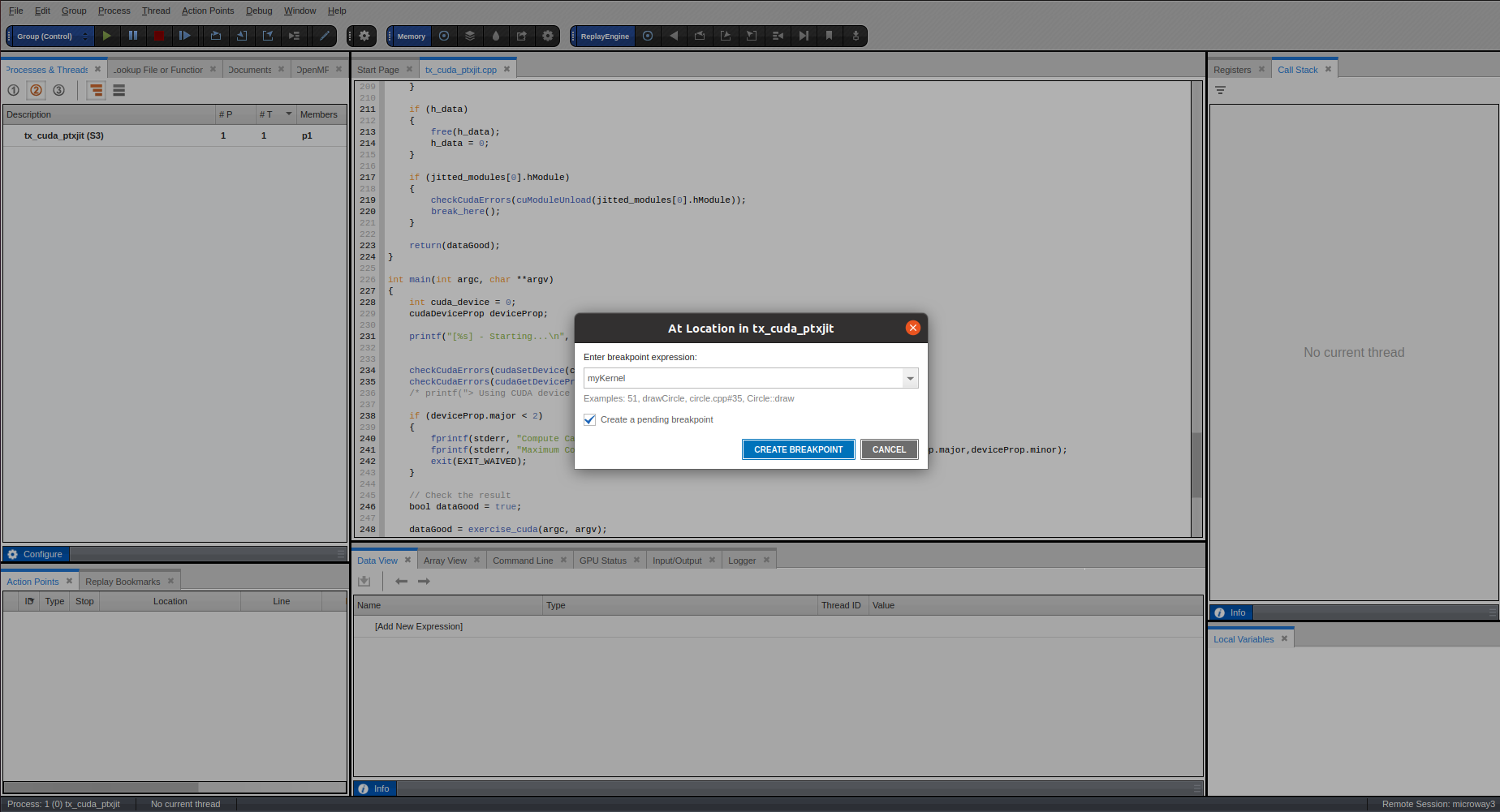 Back to top
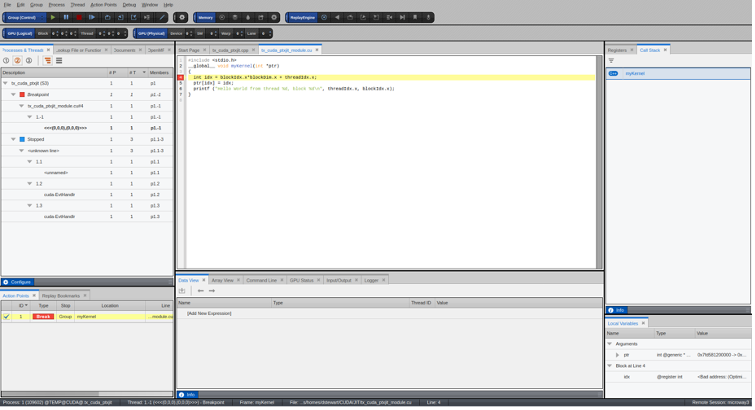
Back to topRun to the Kernel breakpoint
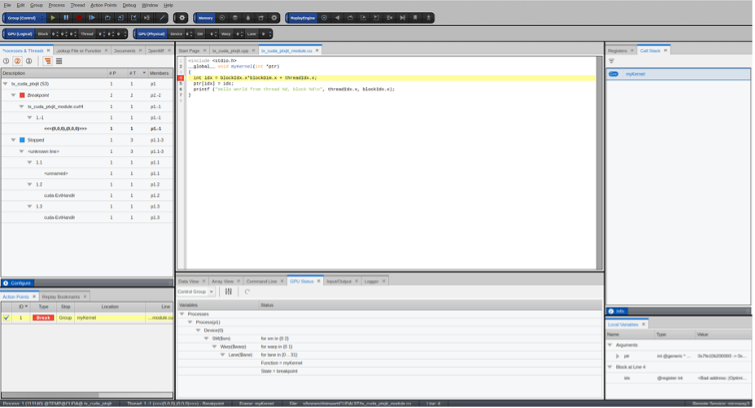
Select the GPU Status tab to view additional information about the kernel launch
tx_cuda_ptxjit.cpp
/**
* Copyright 1993-2014 NVIDIA Corporation. All rights reserved.
*
* Please refer to the NVIDIA end user license agreement (EULA) associated
* with this source code for terms and conditions that govern your use of
* this software. Any use, reproduction, disclosure, or distribution of
* this software and related documentation outside the terms of the EULA
* is strictly prohibited.
*
*/
/*
* This sample uses the Driver API to just-in-time compile (JIT) a Kernel from PTX code.
* Additionally, this sample demonstrates the seamless interoperability capability of CUDA runtime
* Runtime and CUDA Driver API calls.
* This sample requires Compute Capability 2.0 and higher.
*
*/
/*
* Update log
*
* Apr 12 2017 JVD: Bug fix TVT-21850: "Debugging multi-process CUDA code runs into
* FERR - already registered with that asect".
* - Modifed so that it will load multiple modules from argv.
* Currently used only for the purpose loading the same
* module multiple times, so that we get the same CUDA ELF
* image loaded into the device at different addresses.
* Apr 2 2014 MCH: Modified to do load and unload twice to test cuda kernel breakpoints
* span a unload - loads. This program is used by tx_cuda_module_unload.tst.
* Fixes TVT-16369.
*/
// System includes
#include <iostream>
#include <math.h>
#include <string.h>
#include <stdio.h>
#include <assert.h>
// CUDA driver & runtime
#include <cuda.h>
#include <cuda_runtime.h>
/* EXIT_ defines */
#define EXIT_FAILURE 1
#define EXIT_WAIVED 2
template< typename T >
void check(T result, char const *const func, const char *const file, int const line)
{
if (result)
{
fprintf(stderr, "CUDA error at %s:%d code=%d \"%s\" \n",
file, line, static_cast<unsigned int>(result), func);
cudaDeviceReset ();
// Make sure we call CUDA Device Reset before exiting
exit(EXIT_FAILURE);
}
}
#define checkCudaErrors(val) check ( (val), #val, __FILE__, __LINE__ )
const char *sSDKname = "PTX Just In Time (JIT) Compilation (no-qatest)";
struct jitted_module_t
{
CUmodule hModule;
CUfunction hKernel;
CUlinkState lState;
bool valid;
jitted_module_t() : hModule(0), hKernel(0), lState(0), valid(false) {}
};
bool ptxJIT(const char *ptx_path, jitted_module_t *jitted_module)
{
CUjit_option options[6];
void *optionVals[6];
float walltime;
char error_log[8192],
info_log[8192];
unsigned long logSize = 8192;
void *cuOut;
size_t outSize;
int myErr = 0;
// Setup linker options
// Return walltime from JIT compilation
options[0] = CU_JIT_WALL_TIME;
optionVals[0] = (void *) &walltime;
// Pass a buffer for info messages
options[1] = CU_JIT_INFO_LOG_BUFFER;
optionVals[1] = (void *) info_log;
// Pass the size of the info buffer
options[2] = CU_JIT_INFO_LOG_BUFFER_SIZE_BYTES;
optionVals[2] = (void *) logSize;
// Pass a buffer for error message
options[3] = CU_JIT_ERROR_LOG_BUFFER;
optionVals[3] = (void *) error_log;
// Pass the size of the error buffer
options[4] = CU_JIT_ERROR_LOG_BUFFER_SIZE_BYTES;
optionVals[4] = (void *) logSize;
// Create a pending linker invocation
checkCudaErrors(cuLinkCreate(5,options, optionVals, &jitted_module->lState));
assert (sizeof(void *)==8);
printf("Loading %s program\n", ptx_path);
myErr = cuLinkAddFile(jitted_module->lState, CU_JIT_INPUT_PTX, ptx_path, 0,0,0);
if (myErr != CUDA_SUCCESS)
{
// Errors will be put in error_log, per CU_JIT_ERROR_LOG_BUFFER option above.
fprintf(stderr,"PTX Linker Error:%d (%s)\n",myErr, error_log);
return false;
}
// Complete the linker step
checkCudaErrors(cuLinkComplete(jitted_module->lState, &cuOut, &outSize));
// Load resulting cuBin into module
checkCudaErrors(cuModuleLoadData(&jitted_module->hModule, cuOut));
// Locate the kernel entry poin
checkCudaErrors(cuModuleGetFunction(&jitted_module->hKernel, jitted_module->hModule, "_Z8myKernelPi"));
// Destroy the linker invocation
checkCudaErrors(cuLinkDestroy(jitted_module->lState));
jitted_module->valid = true;
return true;
}
static void break_here() {
printf ("Break Here\n");
}
#define MAX_JITTED 4
jitted_module_t jitted_modules[MAX_JITTED];
bool exercise_cuda(int argc, char **argv)
{
const unsigned int nThreads = 64;
const unsigned int nBlocks = 2;
const size_t memSize = nThreads * nBlocks * sizeof(int);
int *d_data = 0;
int *h_data = 0;
// Allocate memory on host and device (Runtime API)
// NOTE: The runtime API will create the GPU Context implicitly here
if ((h_data = (int *)malloc(memSize)) == NULL)
{
std::cerr << "Could not allocate host memory" << std::endl;
exit(EXIT_FAILURE);
}
checkCudaErrors(cudaMalloc(&d_data, memSize));
// JIT Compile the Kernel from PTX and get the Handles (Driver API)
assert (argc > 1);
assert ((argc-1) <= MAX_JITTED);
for (int i = 1; i < argc; ++i)
{
jitted_module_t *jitted_module = &jitted_modules[i-1];
bool ret = ptxJIT(argv[i], jitted_module);
if (!ret)
{
fprintf(stderr, "ptxJIT Failed.\n");
return 0;
}
}
assert (jitted_modules[0].valid);
// Set the kernel parameters (Driver API)
checkCudaErrors(cuFuncSetBlockShape(jitted_modules[0].hKernel, nThreads, 1, 1));
int paramOffset = 0;
checkCudaErrors(cuParamSetv(jitted_modules[0].hKernel, paramOffset, &d_data, sizeof(d_data)));
paramOffset += sizeof(d_data);
checkCudaErrors(cuParamSetSize(jitted_modules[0].hKernel, paramOffset));
// Launch the kernel (Driver API_)
checkCudaErrors(cuLaunchGrid(jitted_modules[0].hKernel, nBlocks, 1));
std::cout << "CUDA kernel launched" << std::endl;
// Copy the result back to the host
checkCudaErrors(cudaMemcpy(h_data, d_data, memSize, cudaMemcpyDeviceToHost));
// Check the result
bool dataGood = true;
for (unsigned int i = 0 ; dataGood && i < nBlocks * nThreads ; i++)
{
// printf ("h_data[%d] : %d\n", i, h_data[i]);
if (h_data[i] != (int)i)
{
std::cerr << "Error at " << i << std::endl;
dataGood = false;
}
}
// Cleanup
if (d_data)
{
checkCudaErrors(cudaFree(d_data));
d_data = 0;
}
if (h_data)
{
free(h_data);
h_data = 0;
}
if (jitted_modules[0].hModule)
{
checkCudaErrors(cuModuleUnload(jitted_modules[0].hModule));
break_here();
}
return(dataGood);
}
int main(int argc, char **argv)
{
int cuda_device = 0;
cudaDeviceProp deviceProp;
printf("[%s] - Starting...\n", sSDKname);
checkCudaErrors(cudaSetDevice(cuda_device));
checkCudaErrors(cudaGetDeviceProperties(&deviceProp, cuda_device));
/* printf("> Using CUDA device [%d]: %s\n", cuda_device, deviceProp.name); */
if (deviceProp.major < 2)
{
fprintf(stderr, "Compute Capability 2.0 or greater required for this sample.\n");
fprintf(stderr, "Maximum Compute Capability of device[%d] is %d.%d.\n", cuda_device,deviceProp.major,deviceProp.minor);
exit(EXIT_WAIVED);
}
// Check the result
bool dataGood = true;
dataGood = exercise_cuda(argc, argv);
if (!dataGood)
{
std::cerr << "exercise_cuda failed" << std::endl;
exit(EXIT_FAILURE);
}
dataGood = exercise_cuda(argc, argv);
if (!dataGood)
{
std::cerr << "exercise_cuda second call failed" << std::endl;
exit(EXIT_FAILURE);
}
// cudaDeviceReset causes the driver to clean up all state. While
// not mandatory in normal operation, it is good practice. It is also
// needed to ensure correct operation when the application is being
// profiled. Calling cudaDeviceReset causes all profile data to be
// flushed before the application exits
cudaDeviceReset();
return dataGood ? EXIT_SUCCESS : EXIT_FAILURE;
}
tx_cuda_ptxjit.h
/*
* Copyright 1993-2013 NVIDIA Corporation. All rights reserved.
*
* Please refer to the NVIDIA end user license agreement (EULA) associated
* with this source code for terms and conditions that govern your use of
* this software. Any use, reproduction, disclosure, or distribution of
* this software and related documentation outside the terms of the EULA
* is strictly prohibited.
*
*/
#ifndef _PTXJIT_H_
#define _PTXJIT_H_
/*
* PTX is equivalent to the following kernel:
*
* __global__ void myKernel(int *data)
* {
* int tid = blockIdx.x * blockDim.x + threadIdx.x;
* data[tid] = tid;
* }
*
*/
char myPtx64[] = "\n\
.version 3.2\n\
.target sm_20\n\
.address_size 64\n\
.visible .entry _Z8myKernelPi(\n\
.param .u64 _Z8myKernelPi_param_0\n\
)\n\
{\n\
.reg .s32 %r<5>;\n\
.reg .s64 %rd<5>;\n\
ld.param.u64 %rd1, [_Z8myKernelPi_param_0];\n\
cvta.to.global.u64 %rd2, %rd1;\n\
.loc 1 3 1\n\
mov.u32 %r1, %ntid.x;\n\
mov.u32 %r2, %ctaid.x;\n\
mov.u32 %r3, %tid.x;\n\
mad.lo.s32 %r4, %r1, %r2, %r3;\n\
mul.wide.s32 %rd3, %r4, 4;\n\
add.s64 %rd4, %rd2, %rd3;\n\
.loc 1 4 1\n\
st.global.u32 [%rd4], %r4;\n\
.loc 1 5 2\n\
ret;\n\
}\n\
";
char myPtx32[] = "\n\
.version 3.2\n\
.target sm_20\n\
.address_size 32\n\
.visible .entry _Z8myKernelPi(\n\
.param .u32 _Z8myKernelPi_param_0\n\
)\n\
{\n\
.reg .s32 %r<9>;\n\
ld.param.u32 %r1, [_Z8myKernelPi_param_0];\n\
cvta.to.global.u32 %r2, %r1;\n\
.loc 1 3 1\n\
mov.u32 %r3, %ntid.x;\n\
mov.u32 %r4, %ctaid.x;\n\
mov.u32 %r5, %tid.x;\n\
mad.lo.s32 %r6, %r3, %r4, %r5;\n\
.loc 1 4 1\n\
shl.b32 %r7, %r6, 2;\n\
add.s32 %r8, %r2, %r7;\n\
st.global.u32 [%r8], %r6;\n\
.loc 1 5 2\n\
ret;\n\
}\n\
";
#endif
tx_cuda_ptxjit_module.cu
#include <stdio.h>
__global__ void myKernel(int *ptr)
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
ptr[idx] = idx;
printf ("Hello World from thread %d, block %d\n", threadIdx.x, blockIdx.x);
}
Back to top
